Drupal's Queue API is the Most Underused Feature in Core
Most Drupal teams reach for cron, Batch API, or external job runners when Queue API would solve the problem with less code and fewer moving parts. Three patterns where Queue API earns its place, with snippets and architecture diagrams.
Drupal's Queue API is the Most Underused Feature in Core
Drupal core ships with a perfectly capable async job system. Most teams never touch it. They reach for hook_cron for scheduled work, Batch API for one-shot bulk operations, and external job runners like Redis-backed queues or RabbitMQ for anything that smells serious. Queue API quietly sits in core covering the middle ground between all three, with retry semantics, lease handling, and pluggable backends built in.
This post is about why it gets skipped, what it actually does well, and three architectural patterns where reaching for Queue API first would have saved real time on projects I have seen.
Why Queue API Gets Skipped
Four reasons keep showing up:
The mental model does not match cron. hook_cron answers "run this on a schedule." Queue API answers "run this asynchronously when capacity is available." Teams that have only used cron try to retrofit the cron model onto queues and end up confused about when items actually process.
The documentation is fragmented. The pieces live across api.drupal.org, the Advanced Queue contrib module, old change records from D7, and scattered blog posts. There is no canonical "here is how Queue API fits with everything else in core" guide. Most devs learn it through migration internals because Migrate API is the highest-profile consumer.
The naming is dense. QueueFactory, QueueInterface, ReliableQueueInterface, QueueWorker plugin annotations, DatabaseQueue, SuspendQueueException. None of this is hard once you see it together. None of it is welcoming the first time you encounter it.
Most tutorials show toy examples. "Process a CSV row by row" is fine for learning the API but it does not show the patterns that make Queue API worth reaching for in production. The interesting use cases involve external systems, editorial workflows, and reliability requirements, none of which fit in a 200-line tutorial.
The result is a feature that ships in core, solves real problems elegantly, and gets bypassed in favor of bespoke cron jobs or third-party job runners that recreate what core already provides.
The Mental Model in 90 Seconds
Three concepts, then three patterns.
A queue is a named bucket of work items. You create one by name and Drupal lazily backs it with whatever queue backend is configured (database by default, Redis or Beanstalkd via contrib).
A queue item is any serializable PHP value (usually an array or simple object) that represents one unit of work.
A QueueWorker is a plugin that knows how to process one item. It is the only piece you really write. Drupal handles the claim, the lease, the release on success, and the requeue on failure.
// Create or get a queue, push an item.
$queue = \Drupal::service('queue')->get('custom_pim_sync');
$queue->createItem(['product_id' => 12345, 'attempt' => 1]);
// src/Plugin/QueueWorker/PimSyncWorker.php
namespace Drupal\custom\Plugin\QueueWorker;
use Drupal\Core\Queue\QueueWorkerBase;
use Drupal\Core\Queue\SuspendQueueException;
/**
* @QueueWorker(
* id = "custom_pim_sync",
* title = @Translation("PIM product sync"),
* cron = {"time" = 60}
* )
*/
class PimSyncWorker extends QueueWorkerBase {
public function processItem($data) {
// Do the work. Throw on retry. Throw SuspendQueueException to stop the run.
}
}
That is the whole surface. The cron annotation tells Drupal to spend up to 60 seconds per cron run draining this queue. You can also run it on demand with drush queue:run custom_pim_sync or process it from your own scheduler entirely.
Now the patterns.
Pattern 1: External API Sync With Retry and Backoff
The problem appears on almost every B2B Drupal project. You need to sync content with a third-party system. A PIM, a CRM, a marketing automation tool, an inventory system. The third party will be slow, rate-limited, occasionally down, and never as reliable as your local stack.
The default instinct is to write a hook_cron that loops through entities and calls the API. This works until the third party starts returning 429 or times out. Then half your sync silently fails, you have no record of which items, and the next cron run repeats the same failures.
Queue API handles this natively. Each item is its own retry unit. Failures requeue automatically. You can throw SuspendQueueException to stop the run cleanly when the third party rate-limits you, and the remaining items wait for the next cron tick.
The worker pattern looks like this:
public function processItem($data) {
try {
$response = $this->pimClient->pushProduct($data['product_id']);
}
catch (TooManyRequestsException $e) {
// Stop the whole run. The rest of the queue waits for next cron.
throw new SuspendQueueException('PIM rate limit hit, suspending.');
}
catch (\Exception $e) {
// This item failed but the queue continues. Item requeues automatically.
$this->logger->warning('Item failed: @id', ['@id' => $data['product_id']]);
throw $e;
}
// Mark the source entity as synced.
$this->markSynced($data['product_id']);
}
Two things this gives you for free. Items that fail get retried on the next run without you writing retry bookkeeping. Rate-limit responses stop the queue cleanly, which means you do not hammer a third party that already told you to back off.
Pair this with the Advanced Queue contrib module if you need exponential backoff between retries. Core handles immediate retry. Advanced Queue handles delayed retry, max-attempts caps, and a UI to inspect failures.
Pattern 2: Move Heavy Logic Out of Entity Hooks
The editorial team is complaining that saving a node takes eight seconds. You audit the codebase and find six different hook_entity_update implementations doing work that has nothing to do with the save itself: regenerating image derivatives, pushing to a search index, calling a CDN purge endpoint, sending Slack notifications, syncing to a marketing tool.
None of this work needs to happen synchronously. The editor does not care if the Slack notification fires 30 seconds later. They care that the save returns in under a second.
Queue API turns this into a one-line fix per hook. The hook pushes an item. The QueueWorker does the work asynchronously. The editor gets their save back instantly.
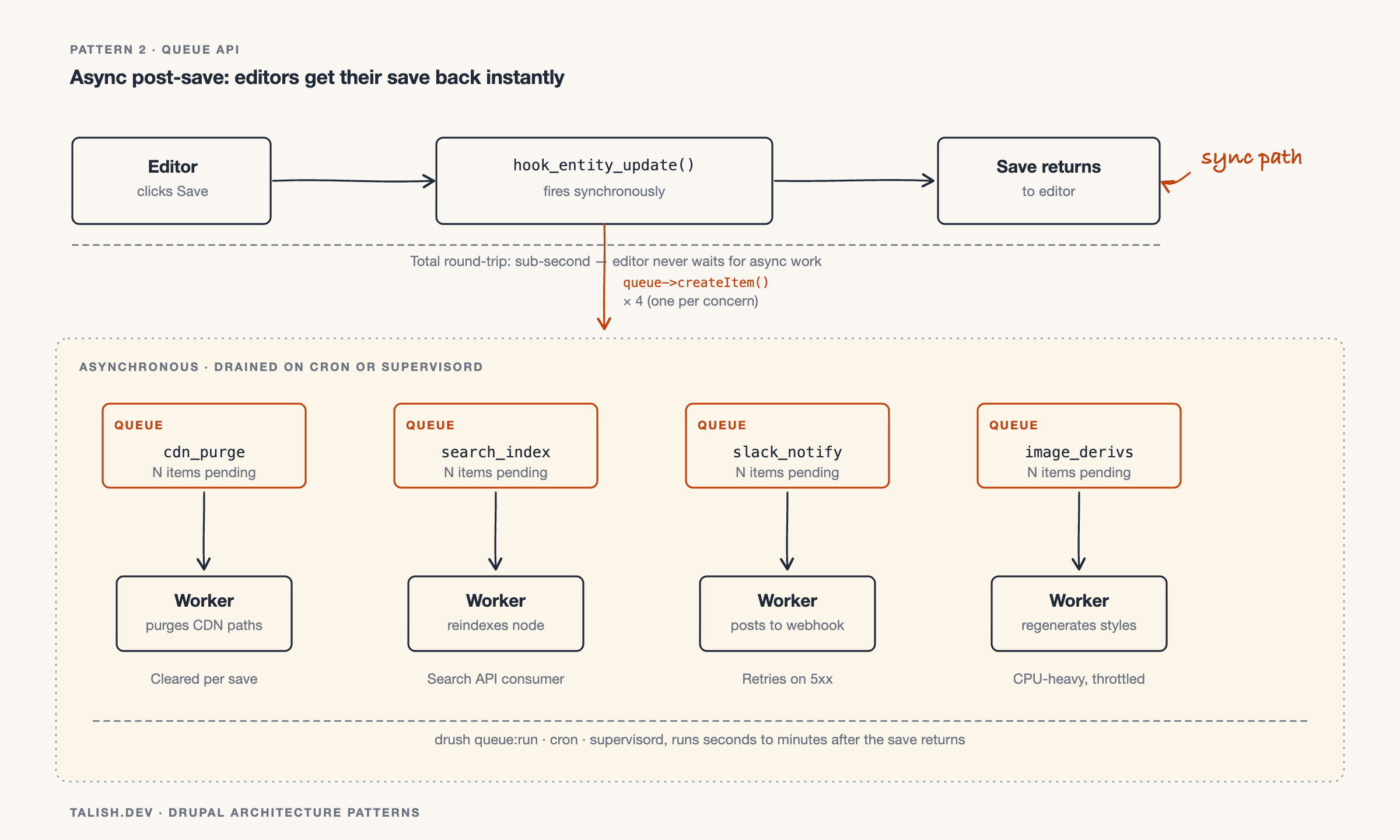
The hook becomes trivial:
function custom_entity_update(EntityInterface $entity) {
if ($entity->getEntityTypeId() !== 'node') {
return;
}
$queue = \Drupal::service('queue');
$payload = ['entity_type' => 'node', 'id' => $entity->id()];
$queue->get('custom_cdn_purge')->createItem($payload);
$queue->get('custom_search_index')->createItem($payload);
$queue->get('custom_slack_notify')->createItem($payload);
}
Three notes on doing this right:
- Use one queue per concern, not one queue for "all post-save work." Different concerns have different retry needs and different processing times. Mixing them means a slow worker blocks fast ones.
- Pass entity IDs in the payload, not entity objects. Load the entity fresh inside the worker. The entity in memory at save time may not match the persisted state by the time the worker runs.
- Be deliberate about what runs on cron versus what runs on a faster scheduler. Cron defaults to every three hours on many sites. For notifications, that is too slow. Run those queues from a dedicated scheduler with shorter intervals.
This pattern alone has fixed editorial performance complaints on more than one project I have worked on.
Pattern 3: Bulk Operations That Outgrow Batch API
Batch API is one of Drupal's best features for bulk operations that complete in a single request lifecycle. It breaks long-running work into chunks the browser can survive.
It breaks down when the operation is too large to reasonably ask the browser to wait for, when the operation needs to span multiple servers, or when it needs to resume cleanly after interruption.
Reindexing 200,000 nodes after a search schema change. Regenerating image derivatives across a media library. Reprocessing every product after a price calculation rule update. Batch API can technically do all of these, but the operator is babysitting a browser tab for hours.
Queue API handles this without ceremony. A drush command (or a button in an admin form) seeds the queue with one item per entity. The queue workers drain it on their own schedule, across whatever workers you have running. The operator closes their laptop and the work continues.
The seeding command:
// In a Drush command.
public function reindexAll() {
$queue = \Drupal::service('queue')->get('custom_reindex');
$nids = \Drupal::entityQuery('node')->accessCheck(FALSE)->execute();
foreach (array_chunk($nids, 100) as $chunk) {
foreach ($chunk as $nid) {
$queue->createItem(['nid' => $nid]);
}
}
$this->output()->writeln(count($nids) . ' items queued.');
}
Then process the queue from N parallel workers using drush queue:run custom_reindex running in supervisord, systemd, or a CI-driven worker fleet. If the operation gets interrupted, it resumes from wherever it left off. If a few items fail, they requeue and you fix the underlying issue without restarting the whole operation.
This is the pattern Migrate API uses internally. There is no reason your application code cannot use the same primitives.
When Not to Reach for Queue API
Three cases where I would not use it:
The work is truly real-time. A user clicks a button and expects something to happen in their next page render. Queue API runs asynchronously by definition. If you need sub-second user-facing response, you need a different tool or a synchronous code path.
The work needs distributed coordination. If multiple Drupal servers need to coordinate the work, agree on order, or share state during processing, Queue API's database backend will not give you what you need. Reach for a proper job runner with locking primitives.
The work runs once and only once. Some operations must run exactly once across an entire cluster, with strong guarantees. Queue API gives you at-least-once delivery. If you need exactly-once, you need either application-level idempotency (often the right answer) or a different system.
For everything in the middle, which is most asynchronous work on most Drupal sites, Queue API is the right starting point.
Closing Thought
Most teams write Queue API equivalents from scratch without realizing it. They build retry logic into cron hooks, they pile post-save work into entity hooks, they spawn external job runners for problems core already solves. The reflex to reach for something else is partly historical, partly documentation-driven, and partly cultural.
The fix is to learn what Queue API is good at and let it earn its place in your architecture. Three patterns, three real problems, and very little code. That is unusually good leverage for a feature that ships in core.
If you are already running Queue API in production, I would be curious which patterns have worked for you and which fell apart at scale. The honest failure modes are harder to find in writing than the success stories.
Read next
- Jun 23, 2026
I Keep Evaluating Alternatives to Drupal. I Keep Choosing Drupal. Here Is the Actual Reasoning.
I don't ignore the alternatives to Drupal. Sanity, Payload, Strapi, custom Next.js builds. I've built real things with several of them. When a project's requirements push me to look elsewhere, I take them seriously. Here is the honest reasoning behind why I keep choosing Drupal anyway.
- May 25, 2026
Stop Making Users Pay for Work Your CI Pipeline Could Do
Most slow Drupal sites are not slow because the code is wrong. They are slow because expensive work runs at request time when it could have run in the CI pipeline instead. Cold caches, image derivatives, search indexes. The pattern repeats. The fix is the same in every case: move the cost off your users and onto a controlled environment where nobody is waiting. This is a principle, not a tip. Three examples below to make it concrete.
- May 15, 2026
Drupal Got Cache Invalidation Right. The Rest of the Industry Is Catching Up.
Drupal's cache tag system is one of the better-designed cache invalidation models in modern web frameworks. A practitioner's look at why it works, where it breaks across system boundaries, and the mental model that travels to any stack.